KMP, Trie, Aho-Corasick
문자열 A에서 문자열 B를 찾는다고 가정합시다. 보통 문자열 알고리즘을 배울 때 A를 짚더미, B를 바늘이라고도 표현합니다. 대부분의 경우 A가 매우 길고 그에 비해 B가 매우 짧기 때문입니다. 설명의 편의를 위하여 앞으로 A의 길이를 n, B의 길이를 m이라고 하겠습니다.
가장 나이브하게 두 문자열을 비교하는 방법의 시간복잡도는 O(n*m)입니다. 반복문 2개를 사용하여 모든 문자를 비교하는 방법입니다.
하지만 KMP 알고리즘을 사용한다면 우리는 시간복잡도를 O(n+m)으로 줄일 수 있습니다. 악명 높은 문자열 비교 알고리즘의 첫번째, KMP를 소개해 드리도록 하겠습니다.
1. KMP 알고리즘
KMP 알고리즘의 핵심은 pi 배열과 two pointer입니다. 일단 pi 배열(실패 함수)에 대해 알아보도록 하겠습니다.
anana라는 단어 s가 있다고 합시다. pi[i]에는 s[0:i]에서 꼬리와 머리가 일치하면서 가장 긴 길이가 저장됩니다.
pi[0]=1 (a = a) pi[1]=0 pi[2]=3 (ana = ana) pi[3]=0
잠깐 예제를 볼까요? AAABBBCCC 와 ABBBC를 나이브하게 비교한다고 가정합시다.
AAABBBCCC ABBBC 0ABBBC 00ABBBC
이런 경우, 처음부터 다시 비교해야 하는데 아깝습니다. 기존에 저장되어 있는 정보를 활용할 수는 없을까요? 이때 쓰는 것이 실패 함수입니다.
우리는 위에서 꼬리와 머리가 같은 최대 길이를 구했습니다. 머리를 꼬리로 쓸 수 있도록 jump해주자는 아이디어가 pi배열의 아이디어입니다.
나머지는 코드를 보고 설명하도록 하겠습니다.
int pi[SZ];
void bkmp(string &s){
int sl=s.size();
int bgn=1, mch=0;
while(bgn+mch<sl){
if(s[mch]==s[bgn]){
mch++;
pi[bgn+mch-1]=mch; // mch는 개수(1 base)이므로 index에서는 -1
}
else{
if(mch==0) bgn++;
else{
bgn+=(mch-pi[mch-1]);
mch=pi[mch-1];
}
}
}
}
int kmp(string &s, string &t){
int sl=s.size(); int tl=t.size();
int res=0, bgn=0, mch=0;
while(bgn+mch<sl){
if(s[bgn+mch]==t[mch]){
mch++;
if(mch==tl) res++;
}
else{
if(mch==0) bgn++;
else{
bgn+=(mch-pi[mch-1]);
mch=pi[mch-1];
}
}
}
return res;
}
bkmp는 실패함수를 구하는 과정이고 kmp는 두 문자열을 비교하는 과정입니다. 하지만 bkmp와 kmp는 코드 상 몹시 유사합니다.
우리는 bgn, mch라는 2개의 포인터를 잡습니다. bgn(begin)은 원본 문자열의 위치, mch(match)는 문자열이 연속으로 몇 개 일치하는가를 나타냅니다.
참고로, bkmp에서는 같은 문자열에서 꼬리와 머리의 일치를 찾는 것이므로 초기에 bgn을 1로 설정합니다. kmp에서는 다른 문자열을 비교하는 것이므로 초기에 bgn을 0으로 설정합니다.
2. TRIE
여러개의 문자열 중에서 문자열 하나를 빠르게 찾을때 필요한 자료구조가 TRIE라는 자료구조입니다. 이후에 아호코라식 알고리즘에서도 트라이를 사용하기 때문에 확실하게 익히고 넘어가시는 걸 추천드립니다.
Trie의 형태는 다음과 같습니다.
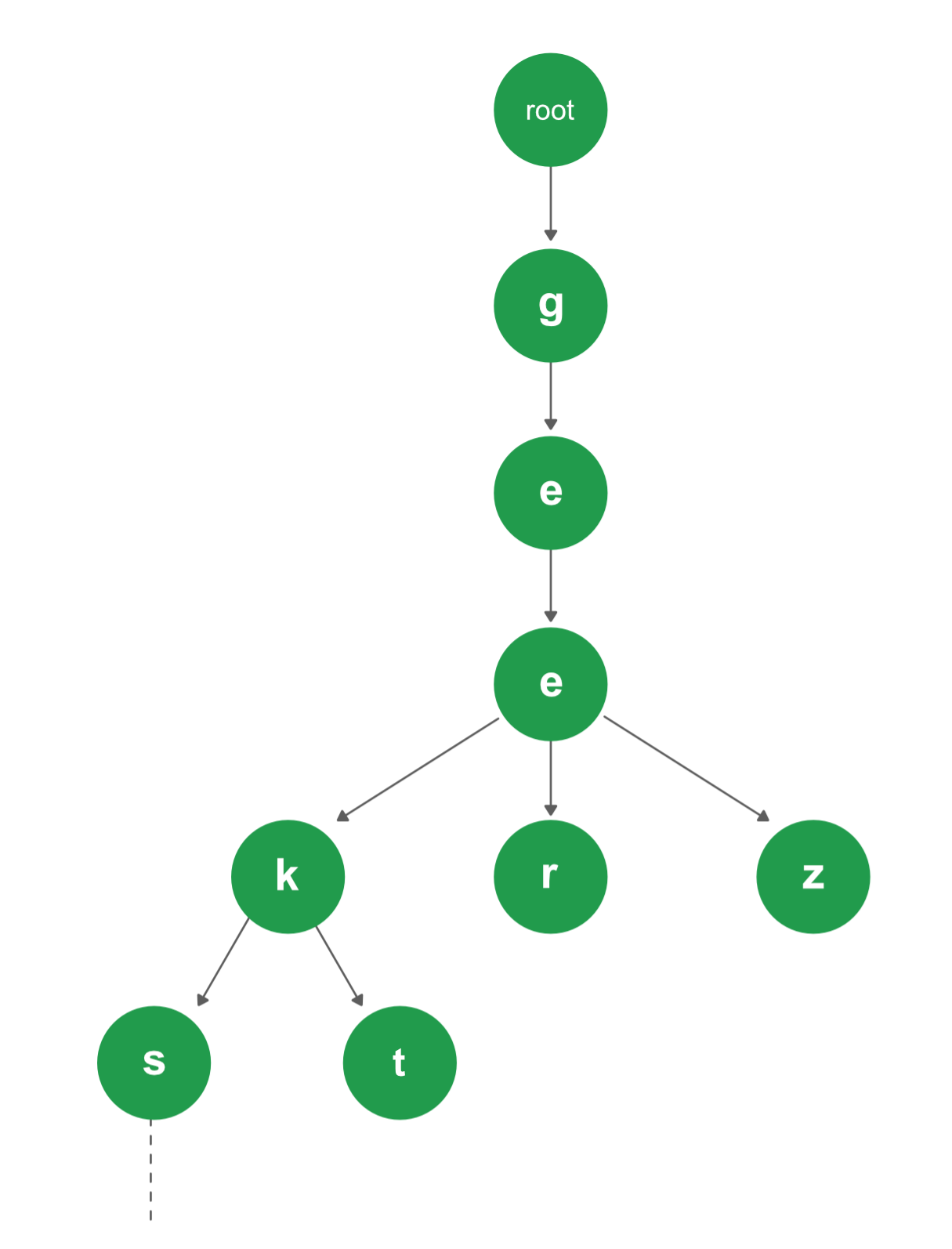
이미지는 이번에도 geeksforgeeks에서 가져왔습니다. ㅎㅎ
Trie Update
Trie 자료구조에 geekt, geer, geez, geeksforgeeks를 저장해봅시다. 처음 트라이에는 root 만 존재합니다. 여기에 geekt를 저장하기 위해서 우리는 루트에 g라는 노드를 추가합니다. 마찬가지로 g에 e를, e에 e를… 추가합니다. 그림처럼 말이죠.
이제 우리는 geer를 저장할겁니다. 루트에 g라는 노드가 이미 연결되어 있기 때문에 새로 g를 만들 필요가 없습니다. g로 갑니다. 마찬가지로 e,e로 가봅시다. 이제 우리는 r을 저장해야 하는데 r이라는 노드가 없기 때문에 r이라는 노드를 새로 만들어주고 단어가 끝났으므로 끝냅니다.
다음 단어들도 같은 방식으로 진행됩니다.
이제 코드를 볼까요? Linked List로 구현해도 되겠지만 간결하게 배열을 이용하여 구현하겠습니다.
int trie[SZ][26];
int frq[SZ];
int tot;
void update(string &x){
int p=0;
int sz=(int)x.size();
for(int i=0;i<sz;i++){
if(!trie[p][x[i]-'a']) trie[p][x-'a']=++tot;
p=trie[p][x-'a'];
}
}
백준 5670 휴대폰 자판
휴대폰 자판 문제의 정답코드를 보겠습니다. 사실 트라이만을 이용하면 사간제한이 빡빡하여 트라이+dp를 사용하는게 정해인 듯 하지만 일단 제 코드는 통과했으므로 여기서 소개합니다. ㅎㅎ
트라이에 단어들을 update하고 trie에서 단어를 찾는 과정에서 다른 알파벳이 없으면 휴대폰이 그 알파벳을 자동으로 입력해 줍니다. 하지만 hell과 hello의 경우 o에서 다른 알파벳이 존재하지 않지만 휴대폰이 o를 입력해 주지는 않습니다. hell 인지 hello인지 애매하기 때문이죠.
따라서 저는 종결 알파벳($ \epsilon $) 을 추가하여 사전에 넣어주었습니다. (코딩의 편의를 위하여 ‘z’+1을 $ \epsilon $ 대신 추가하였습니다. ) 이렇게 되면 hello와 hell이 애매해질 걱정이 없습니다.
#include<bits/stdc++.h>
#define pb push_back
using namespace std;
const int SZ=1000005;
vector<string> dict;
int trie[SZ][30];
int tot;
struct Trie{
Trie(){
memset(trie,0,sizeof(trie));
dict.clear();
tot=0;
}
void update(string &x){
int p=0;
int sz=(int)x.size();
for(int i=0;i<sz;i++){
if(!trie[p][x[i]-'a']) trie[p][x[i]-'a']=++tot;
p=trie[p][x[i]-'a'];
}
}
int find(string &x){
int res=1, p=trie[0][x[0]-'a'];
int sz=(int)x.size();
for(int i=1;i<sz-1;i++){
bool flg=false;
for(int j=0;j<27;j++){
if(j!=x[i]-'a' && trie[p][j]) flg=true;
}
if(flg) res++;
p=trie[p][x[i]-'a'];
}
return res;
}
};
int main(void){
ios_base::sync_with_stdio(false); cin.tie(NULL);
int n;
while(cin>>n){
Trie tr=Trie();
for(int i=0;i<n;i++){
string x; cin>>x;
x+=('z'+1);
dict.pb(x);
tr.update(x);
}
int ans=0;
for(int i=0;i<n;i++){
ans+=tr.find(dict[i]);
}
cout<<fixed; cout.precision(2);
cout<<(double)ans/(double)n<<'\n';
}
return 0;
}
3. 아호 코라식(Aho Corasick) 알고리즘
아호코라식 알고리즘은 사전(여러개의 단어들)을 하나의 문자열에서 찾는 알고리즘입니다. KMP에서 설명했던 실패 함수를 Trie에서 사용하는 멋진 알고리즘이죠. KMP를 사용하여 여러개의 단어를 찾으려면 O(n*z)(n: 짚더미와 바늘의 길이, z: 패턴의 개수) 의 시간복잡도가 걸리는데 이를 O(n+z)로 줄여줍니다. 이렇게 말만 들으면 코드가 복잡할 것 같지만 그렇게 복잡하지는 않습니다.
아호코라식 알고리즘의 개관을 보도록 하겠습니다.
- 사전의 정보를 저장하는 Trie 구성
- BFS를 이용하여 실패함수 생성
- 사전에 있는 단어의 등장 여부 확인
트라이 구성
트라이 구성은 위에서 봤던 방법과 동일합니다. 하지만 우리는 여기서 Output link까지 확인 해 주어야 합니다. Output link는 사전에 있는 단어가 종료되었는지 여부를 나타냅니다. 트라이에서 사전에 있는 단어 (ban)이 다른 단어 (banana)의 sustring이 되어 확인하지 못하는 경우를 막기 위해서 필요합니다. 코드는 간단합니다.
int trie[SZ][26];
bool output[SZ];
int tot;
void update(string &x){
int p=0;
int sz=x.size();
for(int i=0;i<sz;i++){
if(!trie[p][x[i]-'a']) trie[p][x-'a']=++tot;
p=trie[p][x-'a'];
}
output[p]=true;
}
단순히 output배열을 추가해준 것만으로도 output link가 가능합니다. 모든 문자열이 tot라는 값을 가지는 key와 1대1 대응되기 때문이죠.
BFS를 이용하여 실패함수 생성
실패함수는 KMP와 비슷합니다. 문자열을 검색하는 과정에서 검색이 실패했다고 하여 루트로 돌아가서 처음부터 찾는 것은 낭비입니다. 따라서 지금까지 찾아왔던 경로를 이용하여 가능성이 있는 substring으로 jump하는 경로(실패함수)를 추가해주는 것입니다.
failure 함수는 어떻게 생성할까요? 어떤 노드 x에 대하여 실패 함수를 y라고 합시다. 아마도 우리는 x 다음에 올 문자인 z를 찾고 싶은데, z가 존재하지 않는 경우에 실패함수를 사용하게 될 것입니다. 그러면 우리가 할 수 있는 일은 x의 실패함수 y로 가서 z가 연결되어 있는지를 확인해 보는 것입니다. z가 연결되어 있지 않다면 다시 y의 실패함수로 가서 탐색 … 이 과정을 계속하게 됩니다.
bfs를 이용하기 때문에 레벨이 낮은 노드들의 실패함수가 모두 저장되어 있음이 보장됩니다. (레벨: 트리의 높이, 트라이는 트리의 형태입니다.) 또, 자명하게도 레벨이 1인 노드들의 실패함수는 모두 루트입니다.
bfs 도중 실패함수에서 종결 link를 만난다면 종결 link를 추가해주어야 합니다. 해당 문자열의 suffix에 사전의 단어가 있다는 뜻이기 때문이죠.
이제 실패함수를 생성하는 코드를 보도록 하겠습니다. (ansemddl97 선배님의 코드, 설명과 구사과님 블로그 코드를 참고했습니다.)
int fail[SZ];
void failure(){
queue<int> q;
for(int i=0;i<26;i++){
if(trie[0][i]) q.push(trie[0][i]);
}
while(!q.empty()){
int x=q.front(); q.pop();
for(int i=0;i<26;i++){
if(trie[x][i]){
int p=fail[x];
while(p && !trie[p][i]) p=fail[p];
p=trie[p][i];
fail[trie[x][i]]=p;
if(output[p]) output[trie[x][i]]=true;
q.push(trie[x][i]);
}
}
}
}
사전에 있는 단어의 등장 여부
위에서 모든 준비가 끝났으므로 찾으면 됩니다!! 코드를 보죠
bool is_exist(string &s){
int p=0;
int sz=s.size();
for(int i=0;i<sz;i++){
while(p && !trie[p][s[i]-'a']) p=fail[p];
p=trie[p][s[i]-'a'];
if(output[p]) return true;
}
return false;
}
백준 9250 문자열 집합 판별
가장 기본적인 아호코라식 문제인 문자열 집합 판별 의 정답 코드를 보겠습니다.
#include<bits/stdc++.h>
using namespace std;
const int SZ=100005;
int trie[SZ][26];
int fail[SZ];
int term[SZ];
struct Ahocorasick{
int tot;
Ahocorasick(){
memset(trie,0,sizeof(trie));
memset(fail,0,sizeof(fail));
memset(term,0,sizeof(term));
tot=0;
}
void update(string &s){
int p=0;
int sz=s.size();
for(int i=0;i<sz;i++){
if(!trie[p][s[i]-'a']) trie[p][s[i]-'a']=++tot;
p=trie[p][s[i]-'a'];
}
term[p]=1;
}
void bfs(){
queue<int> q;
for(int i=0;i<26;i++){
if(trie[0][i]) q.push(trie[0][i]);
}
while(!q.empty()){
int x=q.front(); q.pop();
for(int i=0;i<26;i++){
if(trie[x][i]){
int p=fail[x];
while(p && !trie[p][i]) p=fail[p];
p=trie[p][i];
fail[trie[x][i]]=p;
if(term[p]) term[trie[x][i]]=1;
q.push(trie[x][i]);
}
}
}
}
int query(string &t){
int p=0;
int sz=t.size();
for(int i=0;i<sz;i++){
while(p && !trie[p][t[i]-'a']) p=fail[p];
p=trie[p][t[i]-'a'];
if(term[p]) return 1;
}
return 0;
}
};
int main(void){
ios_base::sync_with_stdio(false); cin.tie(NULL);
Ahocorasick ah=Ahocorasick();
int n; cin>>n;
for(int i=0;i<n;i++){
string x; cin>>x;
ah.update(x);
}
ah.bfs();
int q; cin>>q;
while(q--){
string x; cin>>x;
if(ah.query(x)) cout<<"YES"<<'\n';
else cout<<"NO"<<'\n';
}
return 0;
}