Heavy Light Decomposition Algorithm
Heavy Light Decomposition Algorithm
HLD란?
트리에서 두 정점 u와 v 사이의 경로에 대해 구간 쿼리(합, 최댓값, 토글 등)를 빠르게 처리하는 대표적인 기법이 Heavy Light Decomposition (HLD) 입니다. 핵심 아이디어는 트리를 여러 개의 chain(연속 경로) 으로 분해한 뒤, 각 chain을 배열의 연속 구간으로 매핑해 세그먼트 트리/펜윅 트리 같은 선형 구조로 처리하는 것입니다.
이번 글에서는 HLD의 정의와 핵심 성질을 정리하고, 구현 관점도 간단히 설명해보겠습니다 :)
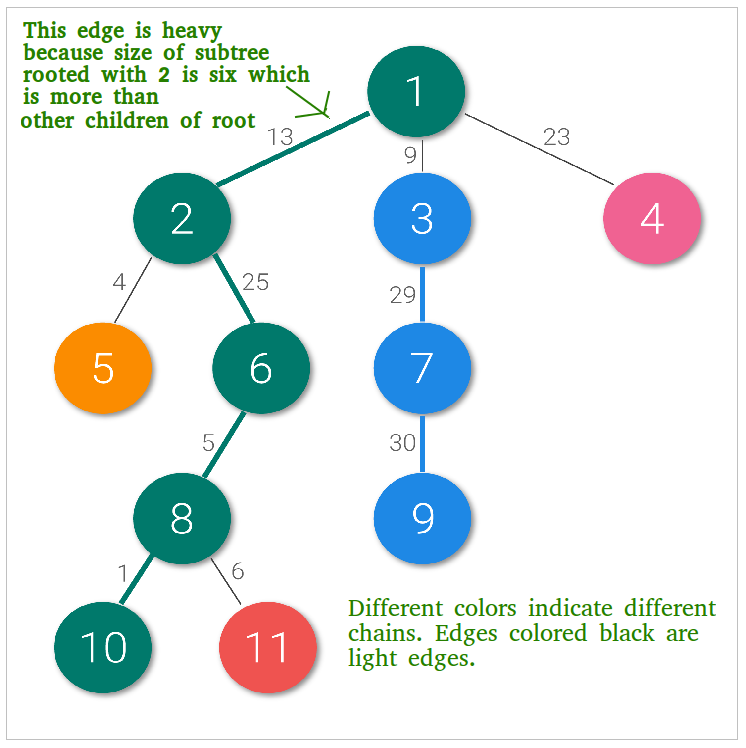
정의: Heavy / Light Edge
루트를 1로 고정했다고 가정합니다.
- 각 정점
x에 대해sub(x)를x를 루트로 하는 서브트리의 크기라고 하겠습니다. x의 자식들 중 서브트리 크기가 가장 큰 자식을 heavy child 라고 합니다. (동률이면 임의 선택)x -> heavy child간선은 heavy edge, 나머지 자식으로 가는 간선은 light edge 입니다.
이때 heavy edge를 따라 연결된 최대 경로 를 heavy chain 이라고 부릅니다.
geeks-for-geeks에서 가져온 그림을 보겠습니다. :)
핵심 정리
정리 1. 임의의 정점 v에 대해, 루트에서 v까지의 경로에 포함된 light edge의 개수는 O(log n) 이하이다.
증명. 어떤 정점 x에서 light edge를 따라 자식 y로 내려갔다고 하자. y는 heavy child가 아니므로
sub(y) <= sub(x) / 2
가 항상 성립합니다. 따라서 root에서 시작해 light edge를 한 번 지날 때마다 서브트리 크기는 최소 절반 이하로 감소합니다.
초기 크기가 n이므로, light edge를 k번 지나면 서브트리 크기는 <= n / 2^k 입니다. 이 값이 1 이상이어야 하므로
2^k <= n => k <= floor(log2 n)
즉 root-to-node 경로에서 light edge 개수는 O(log n)입니다. QED.
정리 2. 임의의 두 정점 u, v 사이의 경로는 O(log n)개의 chain 구간으로 분해된다.
증명. u -> LCA(u,v)와 v -> LCA(u,v) 두 경로를 각각 생각하면, 각 경로는 정리 1에 의해 O(log n)개의 light edge를 넘지 않습니다. 각 light edge는 chain 경계 하나를 만들므로 전체 경로는 O(log n)개의 chain 구간으로 분해됩니다. QED.
heavy chain에 속한 정점들은 배열에서 연속한 구간으로 매핑할 수 있으므로, 각 chain 구간은 segment tree나 fenwick tree 등으로 처리할 수 있습니다. 그리고 임의의 경로는 O(log n)개의 chain 구간으로 분해되므로, 경로 쿼리를 O(log^2 n)에 처리할 수 있습니다.
체인 분해와 배열 매핑
init_dfs(p, x)에서par[x]를 부모로 기록하고,chi[x]에x의 서브트리 크기를 저장합니다.chain_partitioning(g, x)에서는 현재 정점x를 chain 번호g에 넣고,num[x]=++tot로 방문 순서를 붙입니다. 또rev[num[x]]=x를 저장해서 배열 인덱스로 다시 정점을 찾을 수 있게 합니다.
여기서 체인 분해의 핵심은 graph[x]를 한 번 정리한 뒤, 가장 무거운 자식이 graph[x][0]에 오게 만든다는 점입니다.
- 부모
par[x]가 섞여 있으면 먼저 뒤로 보내고 - 자식들 중
chi[]가 가장 큰 정점을 앞으로 보내고 - 그 뒤
graph[x][0]은 현재 정점과 같은 chain 으로 내려가고, 나머지 자식들은 각각 새 chain의 시작점 이 됩니다.
정리하면, 이 구현에서
chi[]는 서브트리 크기grp[]는 chain의 대표 정점num[]는 선형 배열로 펴 놓은 위치rev[]는 그 위치의 원래 정점 번호
를 뜻하고, 경로 쿼리는 여러 개의 [num[l], num[r]] 구간 쿼리로 바뀌게 됩니다.
Complexity
- 전처리(DFS 2회):
O(n) - 경로 쿼리:
O(log^2 n)(chain 수O(log n)× 구간 쿼리O(log n)) - 세그먼트 트리를 사용하면 각 구간 쿼리는
O(log n)
구현
HLD 구현체는 chain partitioning까지는 비슷하지만, 쿼리 함수가 적용되는 문제(자료구조)마다 달라집니다.
const int SZ=100'005;
vi graph[SZ];
int par[SZ], chi[SZ];
int num[SZ], rev[SZ], grp[SZ];
int tot;
int n;
// calc child_num
// p:parent, x: current node
int init_dfs(int p, int x){
par[x]=p;
chi[x]=1;
for(int adj:graph[x]){
if(adj==p) continue;
chi[x]+=init_dfs(x,adj);
}
return chi[x];
}
// chain partitioning
// g:group number, x:current node
void chain_partitioning(int g, int x){
grp[x]=g; // chain grouping
num[x]=++tot; // dfs ordering
rev[tot]=x;
// pop parent(send back, then pop-back)
// left-most child is same color(group, g) with current node
// other child start new chain
for(int i=0;i<(int)graph[x].size();i++){
int adj=graph[x][i];
if(i!=graph[x].size()-1 && adj==par[x]){
swap(graph[x][i],graph[x].back());
adj=graph[x][i];
}
if(adj!=par[x] && chi[adj]>chi[graph[x][0]]){
swap(graph[x][i],graph[x][0]);
}
}
if(!graph[x].empty() && graph[x].back()==par[x]) graph[x].pop_back();
for(int i=0;i<(int)graph[x].size();i++){
if(i==0) chain_partitioning(g,graph[x][i]);
else chain_partitioning(graph[x][i],graph[x][i]);
}
}
주석으로 설명을 달아두었으니 참고하면 됩니다.
쿼리 함수 관련 코드는 아래 예시 문제를 통해 확인할 수 있습니다.
1번을 루트로 하는 트리를 HLD로 구성했다고 합시다.
정점 번호가 DFS ordering 기준이면 1 -> v 경로에서 1이 가장 앞에 옵니다. (이 점은 DFS ordering을 정의한 방식에 따라 바뀔 수 있습니다.)
이 문제에서는 각 chain 구간마다 set을 이용해 최소값(가장 앞 정점)을 관리하면 됩니다.
시간복잡도는 O(m log n)에 가까운 O(m log^2 n)인데, naive하게 O(m log^2 n)을 그대로 쓰면 시간 초과가 날 수 있습니다.
set으로 관리되는 1번 쿼리가 들어올 때마다 set에서 최소 위치 정보를 갱신하고, 2번 쿼리가 들어오면 v -> 1 경로의 sub chain들을 모아 vector에 넣습니다.
그 vector를 reverse하면 1 -> v 순서가 됩니다. 코드는 아래처럼 구성됩니다.
int query(int v){
if(black.empty()) return -1;
vector<pii> tmp;
while(grp[v]!=1){
tmp.push_back({num[grp[v]],num[v]});
v=par[grp[v]];
}
tmp.push_back({num[grp[v]],num[v]});
reverse(tmp.begin(),tmp.end());
for(auto xx:tmp){
int lft=xx.first, rgt=xx.second;
auto low=black.lower_bound(lft);
if(low!=black.end() && *low<=rgt) return rev[*low];
v=par[grp[v]];
}
return -1;
}
굳이 vector를 reverse하지 않아도 문제는 없지만, set의 원소가 많을 때는 이 방식이 더 효율적일 수 있습니다.
set 말고 세그먼트 트리로 해결하는 문제도 많으니, 상황에 맞게 적용하면 됩니다 :)